char和wchar_t在windows上如何正确使用
一、预备知识
unicode
unicode是一套字符编码标准,它为世界上几乎所有的字符都分别分配了一个唯一的编码,但unicode并没有规定这些编码在计算机中如何表示和存储,字符编码的存储是由具体的编码方案决定的,例如常见的utf-8和utf-16编码方案,它们都是unicode编码的实现方式。
unicode使用‘码点’来表示一个字符的编码,书写格式为U+0023,一个U+前缀加上四位16进制数字,这个概念在golang中得到体现,golang中专门定义了一种unicode码点类型rune,用来保存一个字符在unicode中的编号。
windows中的unicode
很多资料中都会提到,windows内核采用的是unicode编码,这里的unicode实际上指的是utf-16编码,windows内核在二三十年内一直采用的是utf-16编码,直到2015年,windows 10才加入了对utf-8的支持,考虑到utf-16编码在windows系统中的普及程度和不可代替性,我们在提及windows系统中的unicode编码时,通常指的是utf-16编码。
ANSI编码
在windows系统中,经常能看到ANSI编码这一概念,ANSI实际上并不是一种具体的编码,而是一个编码集合,它包含了很多不同国家不同地区的编码,例如GBK、GB2312、GB18030、Big5等,windwos系统根据当前的区域设置(locale),自动选择一种编码作为当前的ANSI编码。
二、char和wchar_t
char和wchar_t是C/C++语言中用于表示字符的两种基本数据类型,而这两种类型中保存的字符具体采用什么编码,则取决于编译器和操作系统,在C/C++语言层面并没有统一规定,因此,在不同的编译器和操作系统中,char和wchar_t的编码方式可能会有所不同。
windows中的char和wchar_t
在windows系统中,char类型用于存储包括ANSI编码、utf-8编码在内的各种编码字符,而wchar_t类型仅用于存储utf-16编码的字符
(下图截取自微软文档) 参考https://learn.microsoft.com/zh-cn/cpp/cpp/char-wchar-t-char16-t-char32-t?view=msvc-170

那么windows系统是如何决定char类型使用什么编码的呢?我们可以通过查看当前的区域设置(locale)来确定
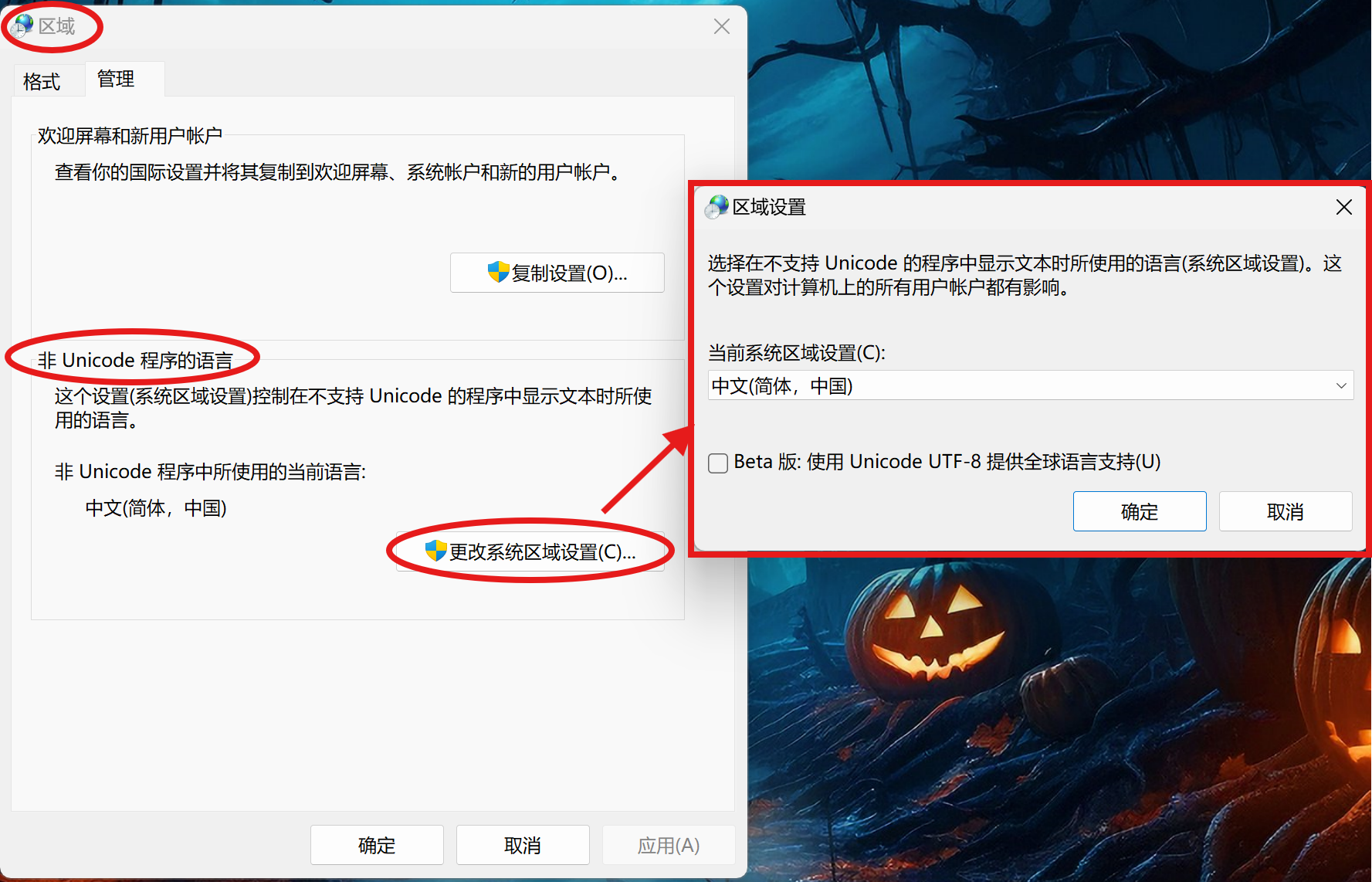
如上图所示,windows区域设置中有一栏叫“非Unicode程序的语言”,这里“非Unicode程序”指的就是使用char类型的程序,因此,这里设置的系统区域决定了char类型使用什么编码,windows会根据当前的系统区域,自动选择一种ANSI编码作为char类型的编码。
同时也可以看到,windows为“非Unicode语言的程序”提供了utf-8支持,也就是说,windows只为char类型提供了utf-8支持,而系统内核依然以utf-16为核心
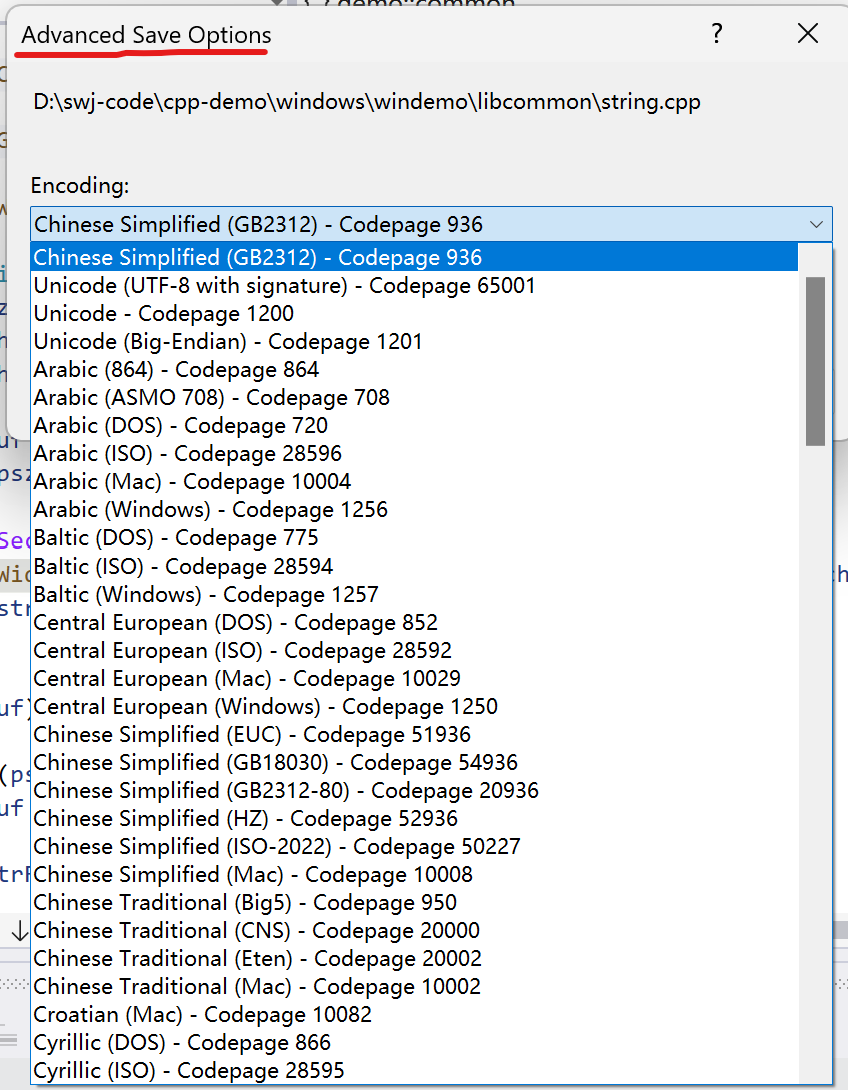
那么如何知道当前系统区域对应的是哪种ANSI编码呢?windows中有一个code page概念,code page是windows操作系统分配给ANSI编码的一个编号,我们可以在很多地方看到code page这个概念,例如,windows的宽字节和多字节字符串相互转换的apiMultiByteToWideChar和WideCharToMultiByte,这两个api的第一个参数都是code page参数,再比如,我们使用visual studio编写代码时,在文件的高级保存选项中,可以看到所有ANSI编码的code page列表,如下图所示
在windows系统中,可以通过chcp命令查看当前的code page,例如在简体中文系统中,chcp命令的输出结果为活动代码页: 936,936这个数字表示当前的ANSI编码为GB2312编码。
三、如何正确使用char和wchar_t
在windows系统下使用char类型的风险
最近在开发过程中就遇到了一个案例,用户电脑的区域设置(locale)是美国,这就意味着,char类型采用的是美国当地的一种编码,而用户创建了一个文件名包含中文字符的文件,我们使用wchar_t类型获取这个文件名时,能够获取到正确的中文字符,因为虽然用户电脑的locale是美国,但windows系统内核是utf-16编码,仍然能够正确的处理中文,但当我们使用WideCharToMultiByteapi把wchar_t类型的字符串转换为char类型后,就出问题了,因为char类型采用的是美国当地的编码,而中文字符在美国的编码中并不存在,因此,转换后的字符串中的中文字符总是乱码。
简单来说,当locale不是中国时,操作系统很有可能识别不了char类型字符串中包含的中文字符,其他非英语国家的语言也是同理。
windows api的A和W版本,优先使用哪个
windows操作系统提供的api一般都分为两个版本,一个后缀为A的版本,和一个后缀为W的版本,A版本api的输入和输出都是char类型,而W版本api的输入和输出都是wchar_t类型。
我们更推荐使用W版的api,如果你跟踪windows程序的调用栈就会发现,A版本的api最终也还是调用了W版本的api,无论是从字符编码的兼容性来讲,还是从调用的效率来讲,W版本的api都更好。
四、结论
在开发windows平台上的C/C++程序时,调用系统api或者标准库api时,优先使用宽字符版本的api,而程序内部需要使用char类型时,则优先使用utf-8编码的char类型,这样的程序兼容性是最好的。